Серверы корпоративных баз данных
Основы конфигурирования серверов баз данных
Одним из наиболее распространенных классов прикладных систем для серверов, выпускаемых большинством компаний-производителей компьютерной техники, являются системы управления базами данных (СУБД). Серверы СУБД значительно более сложны, чем серверы сетевых файловых систем NFS. Стандартный язык реляционных СУБД (SQL) намного богаче, чем набор операций NFS. Более того, имеется несколько популярных коммерческих реализаций СУБД, доступных на серверах различных компаний, каждая из которых имеет совершенно различные характеристики. Вследствие этого последующий материал будет носить достаточно общий характер.
Дело в том, что почти невозможно корректно ответить на вопрос: "Сколько пользователей данного типа будет поддерживать данная система?". В общем случае скорее можно решить, что определенная конфигурация системы не может выполнить данную задачу, чем решить, что данная конфигурация сможет с ней справиться. Например, достаточно просто определить, что система с одним дисковым накопителем не сможет достичь пропускной способности в 130 обращений в секунду при выполнении операций произвольного доступа к диску, поскольку один диск за одну секунду сможет обработать только 65 таких обращений. Однако система с двумя такими дисками либо сможет, либо не сможет справиться с такой нагрузкой, поскольку может случиться, что в системе имеется какое-либо другое узкое место, вовсе не связанное с дисковой подсистемой.
Как приложения, ориентированные на использование баз данных, так и сами СУБД сильно различаются по своей организации. Если системы на базе файловых серверов сравнительно просто разделить по типу рабочей нагрузки на два принципиально различных класса (с интенсивной обработкой атрибутов файлов и с интенсивной обработкой самих данных), то провести подобную классификацию среди приложений баз данных и СУБД просто невозможно.
Хотя на сегодня имеется целый ряд различных архитектур баз данных, рынок
UNIX-систем, кажется, остановился главным образом на реляционной модели. Абсолютное большинство инсталлированных сегодня систем реляционные, поскольку эта архитектура выбрана такими производителями как Oracle, Sybase, Ingres, Informix, Progress, Empress и DBase. ADABAS компании Software AG - иерархическая система, хотя может обрабатывать стандартный SQL.
Но даже с учетом того, что подавляющее большинство систем работает по одной и той же концептуально общей схеме, между различными продуктами имеются большие архитектурные различия. Возможно наиболее существенным является реализация самой СУБД.
Можно выделить два основных класса систем: системы, построенные по принципу "2N" (или "один-к-одному"), и многопотоковые системы (Рисунок 2.1). В более старых
2N-реализациях для каждого клиента на сервере используется отдельный процесс, даже если программа-клиент физически выполняется на отдельной системе. Таким образом, для работы каждого клиентского приложения используются два процесса - один на сервере и один на клиентской системе. Многопотоковые приложения как раз и разработаны для того, чтобы существенно снизить дополнительные расходы на организацию управления таким большим количеством процессов. Обычно они предполагают наличие одного кластера из нескольких процессов (от одного до пяти), работающих на серверной системе. Эти процессы имеют внутреннюю многопотоковую организацию, что обеспечивает обслуживание запросов множества клиентов. Большинство основных поставщиков СУБД в настоящее время используют многопотоковую реализацию или двигаются в этом направлении.
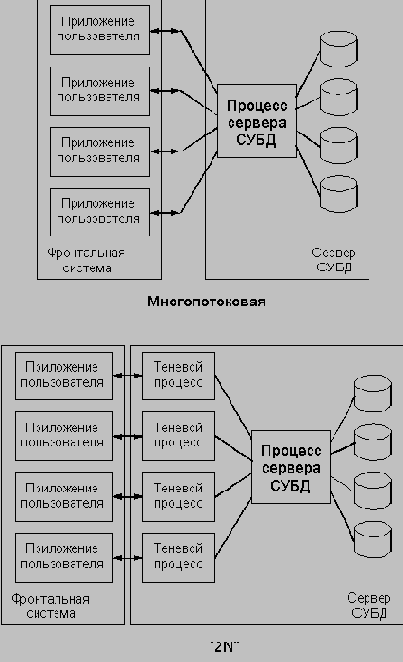
Архитектура СУБД
Таблица 2.1. Архитектура СУБД по поставщикам и версиям
| Многопотоковая | 2N | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Oracle Version 7 (optional) | Oracle Version 6 и по умолчанию Oracle Version 7 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sybase v4.9.x, System10 | Informix v5.x | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ingres v6.x | Ingres v5.x | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Progress version 7 | Progress version 6 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ADABASE version 2.1 |